
charset=cp437 [TXT] [BDF]
This page is a mirror of http://czyborra.com/charsets/codepages.html as on 17-Jun-2004. The original URL is sometimes hard to access.
The industry-standard IBM Personal Computer started out with the famous code page CP437 with lots of box-drawing characters and a select few foreign letters:
Some later MS-DOS versions allowed the changing of code pages on VGA graphics cards to something like CP850 which presented the Latin1 repertoire in positions compatible to CP437 so that line-drawing still worked:
CP852 did the same for Latin2 (Eastern Europe):
CP855 was introduced as the corresponding Cyrillic codepage:
CP855 was soon followed by the CP866 which followed the more logical Russian alphabet ordering of the alternativny variant that was preferred by many Russian users:
The even more widely used Cyrillic charset (KOI8-R) has later been numbered CP878.
Microsoft's Thai CP874 is also following established standards, namely TIS-620, but adds non-standard characters in unused positions:
Now I have spared you the gory details of
With the introduction of Windows, Microsoft dared say goodbye to the line-drawing characters and CP437-compatibility and adopted a modified superset of ISO-8859-1 as CP1252:

charset=Windows-1252
[TXT]
[BDF]
Strange enough, WinLatin2 got the number CP1250 and differs from ISO-8859-2 in some positions but generated a lot of revenue for Microsoft on the emerging markets of Eastern Europe in the 1990s:

charset=Windows-1250
[TXT]
[BDF]
Another such example is the Cyrillic code page CP1251 for which Microsoft registered the label "Windows-1251". As of December 1997, even GOST's new (Lotus Notes) webserver greets you with charset=WINDOWS-1251. GOST (the Russian standardization authority and ISO member body) isn't even following its own standards any more!
CP1251 has a rich repertoire in an ordering incompatible with both ISO-IR-111 (KOI8) and ISO-8859-5:

charset=Windows-1251
[TXT]
[BDF]
This is WinBaltic, which might have served as a model for ISOLatin7:

charset=Windows-1257
[TXT]
[BDF]
Very much unlike the Extended Unix Coding EUC charsets, all of the following East Asian code pages illegaly reuse the C1 control codes {=80..=9F} for their lead bytes and ASCII values {=40..=7E} for their second bytes in order to encode more than ten thousand characters with two bytes. That means that ASCII values beyond =3F in their byte streams do not always mean ASCII characters.
Microsoft is not the only company inventing their own more or less incompatible standards, as you can see in ftp://ftp.unicode.org/Public/MAPPINGS/VENDORS/:
Adobe's PostScript page description language calls its own encoding StandardEncoding and requires that you switch to ISOLatin1Encoding first if you want to print ISO-8859-1 texts.
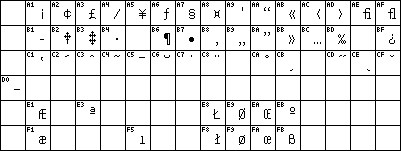
charset=Adobe-Standard-Encoding
[TXT]
[BDF]
Apple's Macintosh has a long tradition of multilingual support on Apple's own charsets of which MacRoman was the first:
NeXTSTEP has something similar:
Hewlett-Packard's HPUX and hpterm have their HP-Roman8:
Send mail to roman@czyborra.com if you need additional fonts or find errors like Andreas Prilop, Kent Karlsson, Jungshik Shin, and Jan Tomasek did.
Roman Czyborra
$Date: 1998/06/27 08:25:38 $







